
はじめに
前回の続きで言語処理100本ノック解いていきたいと思います。
今回は第9章前半です。
9章は非常に盛りだくさんなので3部に分けます。
前回は単層、多層のニューラルネットの実装にチャレンジしましたが、今回はRNN(Recurrent Neural Network)と呼ばれる再帰的構造をもったモデルを使用します。
第9章: RNNとCNN
深層学習フレームワークを用い,再帰型ニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)を実装します.
80. ID番号への変換
問題51で構築した学習データ中の単語にユニークなID番号を付与したい.学習データ中で最も頻出する単語に1,2番目に頻出する単語に2,……といった方法で,学習データ中で2回以上出現する単語にID番号を付与せよ.そして,与えられた単語列に対して,ID番号の列を返す関数を実装せよ.ただし,出現頻度が2回未満の単語のID番号はすべて0とせよ.
まずは前回同様データを学習、検証、評価に分けて前処理しておきます
# データのロード import pandas as pd import re import numpy as np # ファイル読み込み file = './input/section6/newsCorpora.csv' data = pd.read_csv(file, encoding='utf-8', header=None, sep='\t', names=['ID', 'TITLE', 'URL', 'PUBLISHER', 'CATEGORY', 'STORY', 'HOSTNAME', 'TIMESTAMP']) data = data.replace('"', "'") # 特定のpublisherのみ抽出 publishers = ['Reuters', 'Huffington Post', 'Businessweek', 'Contactmusic.com', 'Daily Mail'] data = data.loc[data['PUBLISHER'].isin(publishers), ['TITLE', 'CATEGORY']].reset_index(drop=True) # 前処理 def preprocessing(text): text_clean = re.sub(r'[\"\'.,:;\(\)#\|\*\+\!\?#$%&/\]\[\{\}]', '', text) text_clean = re.sub('[0-9]+', '0', text_clean) text_clean = re.sub('\s-\s', ' ', text_clean) return text_clean data['TITLE'] = data['TITLE'].apply(preprocessing) # 学習用、検証用、評価用に分割する from sklearn.model_selection import train_test_split train, valid_test = train_test_split(data, test_size=0.2, shuffle=True, random_state=64, stratify=data['CATEGORY']) valid, test = train_test_split(valid_test, test_size=0.5, shuffle=True, random_state=64, stratify=valid_test['CATEGORY']) train = train.reset_index(drop=True) valid = valid.reset_index(drop=True) test = test.reset_index(drop=True) # データ数の確認 print('学習データ') print(train['CATEGORY'].value_counts()) print('検証データ') print(valid['CATEGORY'].value_counts()) print('評価データ') print(test['CATEGORY'].value_counts()
以下出力です。
学習データ b 4502 e 4223 t 1219 m 728 Name: CATEGORY, dtype: int64 検証データ b 562 e 528 t 153 m 91 Name: CATEGORY, dtype: int64 評価データ b 563 e 528 t 152 m 91 Name: CATEGORY, dtype: int64
学習データを使って、単語の出現頻度順にidを振った辞書を作成します。
2回以上出てきたものにIDを振り、1回以下のワードは辞書に登録しないでおきます。
# 単語の辞書を作成 from collections import Counter words = [] for text in train['TITLE']: for word in text.rstrip().split(): words.append(word) c = Counter(words) word2id = {} for i, cnt in enumerate(c.most_common()): if cnt[1] > 1: word2id[cnt[0]] = i + 1 for i, cnt in enumerate(word2id.items()): if i >= 10: break print(cnt[0], cnt[1])
出力は以下。
to 1 0 2 in 3 as 4 on 5 UPDATE 6 for 7 The 8 of 9 US 10
最後に文章を入力として、その文中の単語を先頭からID化してリストにする関数を準備します。
# 単語のID化 def tokenizer(text): words = text.rstrip().split() return [word2id.get(word, 0) for word in words] sample = train.at[0, 'TITLE'] print(sample) print(tokenizer(sample))
サンプルの出力結果です
Justin Bieber Under Investigation For Attempted Robbery At Dave Busters [68, 76, 782, 1974, 21, 5054, 5055, 34, 1602, 0]
81. RNNによる予測
問題文長いので割愛しますが、RNNのモデルを作成して、初期値の重みでsoftmaxを計算するというものです。
まず、RNNへの入力として、単語埋め込みベクトルが必要なのでそれについて少し実装テストしてみます。
pytorchにはembeddingというモジュールがあるのでそれを使うことでトークン化された文章(単語のIDを並べたもの)を埋め込みベクトルに変換します。試しにやってみましょう。
VOCAB_SIZEはID化する単語の種類を指定します。今回は試しに0~3の4つなので4です。
EMB_SIZEは埋め込みベクトルのサイズです。適当に3としておきます。
import torch from torch import nn VOCAB_SIZE = 4 EMB_SIZE = 3 emb = nn.Embedding(VOCAB_SIZE, EMB_SIZE) words = torch.tensor([1, 3, 0, 2, 1, 2]) embed_words = emb(words) print(embed_words) print(words.shape, '->', embed_words.shape)
出力は以下。
tensor([[-0.2776, 0.7753, 1.3960],
[ 0.3757, -0.3343, -0.0911],
[-0.1009, 0.6764, -1.0262],
[ 2.1558, 0.7170, 0.4625],
[-0.2776, 0.7753, 1.3960],
[ 2.1558, 0.7170, 0.4625]], grad_fn=<EmbeddingBackward0>)
torch.Size([6]) -> torch.Size([6, 3])nn.Embeddingを使用することでEMB_SIZEの単語ベクトルを単語数分作成するような処理です。
出力の、0、4列目はどちらもID:1の単語ベクトルですが、同じベクトルであることがわかります。
それではこれを踏まえて、RNNの実装をやっていきます。
まずはモデルの作成です。
RNNと同じような原理のLSTMを使用します。RNNを使用したければnn.RNNに変えればOKです。
# RNNの作成 # モデルの構築 import random import torch from torch import nn import torch.utils.data as data from torchinfo import summary # 乱数のシードを設定 # parserなどで指定 seed = 1234 random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.backends.cudnn.benchmark = False torch.backends.cudnn.deterministic = True def seed_worker(worker_id): worker_seed = torch.initial_seed() % 2**32 np.random.seed(worker_seed) random.seed(worker_seed) g = torch.Generator() g.manual_seed(seed) class RNN(nn.Module): def __init__(self, vocab_size, emb_size, padding_idx, hidden_size, output_size, num_layers=1): super().__init__() self.emb = nn.Embedding(vocab_size, emb_size, padding_idx=padding_idx) self.rnn = nn.LSTM(emb_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x, h0=None): x = self.emb(x) x, h = self.rnn(x, h0) x = x[:, -1, :] logits = self.fc(x) return logits # パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 2 # 辞書のID数 + unknown + パディングID EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) + 1 OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 NUM_LAYERS = 1 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, HIDDEN_SIZE, OUTPUT_SIZE, NUM_LAYERS) print(model)
出力は以下の通り
RNN( (emb): Embedding(9725, 300, padding_idx=9724) (rnn): LSTM(300, 50, batch_first=True) (fc): Linear(in_features=50, out_features=4, bias=True) )
のちのち前回までよく使っていた事前学習済みの単語ベクトルを初期値として使用したりしますのでEMB_SIZEはそれに合わせて300次元とします。
最後に初期状態での推論を行います。
x = torch.tensor([tokenizer(sample)], dtype=torch.int64) print(x) print(x.size()) print(nn.Softmax(dim=-1)(model(x)))
結果は以下です。
tensor([[ 68, 76, 782, 1974, 21, 5054, 5055, 34, 1602, 0]]) torch.Size([1, 10]) tensor([[0.2783, 0.2129, 0.2804, 0.2284]], grad_fn=<SoftmaxBackward0>)
82. 確率的勾配降下法による学習
確率的勾配降下法(SGD: Stochastic Gradient Descent)を用いて,問題81で構築したモデルを学習せよ.訓練データ上の損失と正解率,評価データ上の損失と正解率を表示しながらモデルを学習し,適当な基準(例えば10エポックなど)で終了させよ.
まずは前回同様ターゲットをテンソル化しておきます
# ターゲットのテンソル化 category_dict = {'b': 0, 't': 1, 'e':2, 'm':3} Y_train = torch.from_numpy(train['CATEGORY'].map(category_dict).values) Y_valid = torch.from_numpy(valid['CATEGORY'].map(category_dict).values) Y_test = torch.from_numpy(test['CATEGORY'].map(category_dict).values) print(Y_train.size()) print(Y_train)
出力は以下。
torch.Size([10672]) tensor([2, 0, 2, ..., 0, 0, 0])
次にデータセットを作成します。
class NewsDataset(data.Dataset): """ newsのDatasetクラス Attributes ---------------------------- X : データフレーム 単語ベクトルの平均をまとめたテンソル y : テンソル カテゴリをラベル化したテンソル phase : 'train' or 'val' 学習か訓練かを設定する """ def __init__(self, X, y, phase='train'): self.X = X['TITLE'] self.y = y self.phase = phase def __len__(self): """全データサイズを返す""" return len(self.y) def __getitem__(self, idx): """idxに対応するテンソル形式のデータとラベルを取得""" inputs = torch.tensor(tokenizer(self.X[idx])) return inputs, self.y[idx] train_dataset = NewsDataset(train, Y_train, phase='train') valid_dataset = NewsDataset(valid, Y_valid, phase='val') test_dataset = NewsDataset(test, Y_test, phase='val') # 動作確認 idx = 0 print(train_dataset.__getitem__(idx)[0].size()) print(train_dataset.__getitem__(idx)[1]) print(valid_dataset.__getitem__(idx)[0].size()) print(valid_dataset.__getitem__(idx)[1]) print(test_dataset.__getitem__(idx)[0].size()) print(test_dataset.__getitem__(idx)[1])
出力は以下。
torch.Size([10]) tensor(2) torch.Size([11]) tensor(3) torch.Size([13]) tensor(2)
データセットを読み込むためのデータローダーを作成します。
今回はバッチサイズ1です。
# DataLoaderを作成 batch_size = 1 train_dataloader = data.DataLoader( train_dataset, batch_size=batch_size, shuffle=True, worker_init_fn=seed_worker, generator=g) valid_dataloader = data.DataLoader( valid_dataset, batch_size=batch_size, shuffle=False, worker_init_fn=seed_worker, generator=g) test_dataloader = data.DataLoader( test_dataset, batch_size=batch_size, shuffle=False, worker_init_fn=seed_worker, generator=g) dataloaders_dict = {'train': train_dataloader, 'val': valid_dataloader, 'test': test_dataloader, } # 動作確認 batch_iter = iter(dataloaders_dict['train']) inputs, labels = next(batch_iter) print(inputs.size()) print(labels)
出力は以下。
torch.Size([1, 11]) tensor([2])
最後に学習用の関数を定義して学習を行います。5epochで終了させます。
import matplotlib.pyplot as plt from tqdm import tqdm # 学習用の関数を定義 def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs): train_loss = [] train_acc = [] valid_loss = [] valid_acc = [] # epochのループ for epoch in range(num_epochs): print('Epoch {} / {}'.format(epoch + 1, num_epochs)) print('--------------------------------------------') # epochごとの学習と検証のループ for phase in ['train', 'val']: if phase == 'train': net.train() # 訓練モード else: net.eval() # 検証モード epoch_loss = 0.0 # epochの損失和 epoch_corrects = 0 # epochの正解数 # データローダーからミニバッチを取り出すループ for inputs, labels in tqdm(dataloaders_dict[phase]): optimizer.zero_grad() # optimizerを初期化 # 順伝播計算(forward) with torch.set_grad_enabled(phase == 'train'): outputs = net(inputs) loss = criterion(outputs, labels) # 損失を計算 _, preds = torch.max(outputs, 1) # ラベルを予想 # 訓練時は逆伝播 if phase == 'train': loss.backward() optimizer.step() # イテレーション結果の計算 # lossの合計を更新 epoch_loss += loss.item() * inputs.size(0) # 正解数の合計を更新 epoch_corrects += torch.sum(preds == labels.data) # epochごとのlossと正解率の表示 epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset) epoch_acc = epoch_corrects.double() / len(dataloaders_dict[phase].dataset) if phase == 'train': train_loss.append(epoch_loss) train_acc.append(epoch_acc) else: valid_loss.append(epoch_loss) valid_acc.append(epoch_acc) print('{} Loss: {:.4f}, Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc)) return train_loss, train_acc, valid_loss, valid_acc # 学習を実行する # モデルの定義 net = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, HIDDEN_SIZE, OUTPUT_SIZE, NUM_LAYERS) net.train() # 損失関数の定義 criterion = nn.CrossEntropyLoss() # 最適化手法の定義 optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9) num_epochs = 5 train_loss, train_acc, valid_loss, valid_acc = train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs)
学習状況は下記のとおりです。
Epoch 1 / 5 -------------------------------------------- 100%|████████████████████████████████████████████████████████████████████████████| 10672/10672 [02:09<00:00, 82.41it/s] train Loss: 0.9911, Acc: 0.6037 100%|█████████████████████████████████████████████████████████████████████████████| 1334/1334 [00:01<00:00, 798.80it/s] val Loss: 0.7610, Acc: 0.7331 Epoch 2 / 5 -------------------------------------------- 100%|████████████████████████████████████████████████████████████████████████████| 10672/10672 [02:19<00:00, 76.27it/s] train Loss: 0.6174, Acc: 0.7772 100%|█████████████████████████████████████████████████████████████████████████████| 1334/1334 [00:01<00:00, 822.74it/s] val Loss: 0.6286, Acc: 0.7699 Epoch 3 / 5 -------------------------------------------- 100%|████████████████████████████████████████████████████████████████████████████| 10672/10672 [02:19<00:00, 76.65it/s] train Loss: 0.3870, Acc: 0.8584 100%|█████████████████████████████████████████████████████████████████████████████| 1334/1334 [00:01<00:00, 809.27it/s] val Loss: 0.5787, Acc: 0.7856 Epoch 4 / 5 -------------------------------------------- 100%|████████████████████████████████████████████████████████████████████████████| 10672/10672 [02:19<00:00, 76.75it/s] train Loss: 0.2360, Acc: 0.9219 100%|█████████████████████████████████████████████████████████████████████████████| 1334/1334 [00:01<00:00, 893.87it/s] val Loss: 0.6177, Acc: 0.7991 Epoch 5 / 5 -------------------------------------------- 100%|████████████████████████████████████████████████████████████████████████████| 10672/10672 [02:22<00:00, 74.88it/s] train Loss: 0.1439, Acc: 0.9540 100%|█████████████████████████████████████████████████████████████████████████████| 1334/1334 [00:01<00:00, 886.74it/s] val Loss: 0.6454, Acc: 0.7999
83. ミニバッチ化・GPU上での学習
問題82のコードを改変し,B事例ごとに損失・勾配を計算して学習を行えるようにせよ(Bの値は適当に選べ).また,GPU上で学習を実行せよ.
バッチ内で文章内の単語数が異なるので、自動的にバッチ内の文章の最大単語数でそろえるようにします。
この際に短い文章は最後にpadding_idxで指定したidがつくようにデータローダーを改変します。
def collate_fn(batch): sequences = [x[0] for x in batch] labels = torch.LongTensor([x[1] for x in batch]) x = torch.nn.utils.rnn.pad_sequence(sequences, batch_first=True, padding_value=PADDING_IDX) return x, labels # DataLoaderを作成 batch_size = 64 train_dataloader = data.DataLoader( train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn, worker_init_fn=seed_worker, generator=g) valid_dataloader = data.DataLoader( valid_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn, worker_init_fn=seed_worker, generator=g) test_dataloader = data.DataLoader( test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn, worker_init_fn=seed_worker, generator=g) dataloaders_dict = {'train': train_dataloader, 'val': valid_dataloader, 'test': test_dataloader, } # 動作確認 batch_iter = iter(dataloaders_dict['train']) inputs, labels = next(batch_iter) print(inputs) print(labels)
結果は以下の通り。長いので省略します
tensor([[ 163, 2, 288, 7, 1047, 100, 5, 660, 764, 3014, 144, 9724,
9724, 9724, 9724],
[ 503, 1832, 1152, 2497, 1, 6414, 307, 225, 955, 0, 9724, 9724,
9724, 9724, 9724],
[2434, 9, 5591, 5912, 0, 207, 598, 1178, 1039, 11, 1208, 18,
785, 1777, 9724],
...
[1102, 2080, 1102, 2080, 0, 166, 480, 11, 8, 226, 15, 8,
522, 8375, 9724],
[1512, 1070, 1148, 4128, 224, 6697, 1263, 566, 43, 6698, 9724, 9724,
9724, 9724, 9724]])
tensor([0, 0, 2, 0, 3, 2, 2, 0, 1, 0, 2, 0, 2, 2, 2, 0, 1, 0, 1, 0, 0, 3, 2, 0,
3, 2, 0, 2, 1, 0, 0, 2, 0, 0, 1, 2, 0, 3, 2, 1, 2, 0, 0, 0, 3, 0, 0, 0,
0, 2, 0, 0, 2, 0, 0, 0, 0, 0, 0, 2, 3, 2, 2, 1])これで準備OKです。学習用の関数もGPU対応に変更して学習させます。
# 学習を実行する # 学習用の関数を定義 def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs): # 初期設定 # GPUが使えるか確認 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(torch.cuda.get_device_name()) print("使用デバイス:", device) # ネットワークをgpuへ net.to(device) train_loss = [] train_acc = [] valid_loss = [] valid_acc = [] # epochのループ for epoch in range(num_epochs): # epochごとの学習と検証のループ for phase in ['train', 'val']: if phase == 'train': net.train() # 訓練モード else: net.eval() # 検証モード epoch_loss = 0.0 # epochの損失和 epoch_corrects = 0 # epochの正解数 # データローダーからミニバッチを取り出すループ for inputs, labels in dataloaders_dict[phase]: # GPUが使えるならGPUにおっくる inputs = inputs.to(device) labels = labels.to(device) optimizer.zero_grad() # optimizerを初期化 # 順伝播計算(forward) with torch.set_grad_enabled(phase == 'train'): outputs = net(inputs) loss = criterion(outputs, labels) # 損失を計算 _, preds = torch.max(outputs, 1) # ラベルを予想 # 訓練時は逆伝播 if phase == 'train': loss.backward() optimizer.step() # イテレーション結果の計算 # lossの合計を更新 epoch_loss += loss.item() * inputs.size(0) # 正解数の合計を更新 epoch_corrects += torch.sum(preds == labels.data) # epochごとのlossと正解率の表示 epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset) epoch_acc = epoch_corrects.double() / len(dataloaders_dict[phase].dataset) if phase == 'train': train_loss.append(epoch_loss) train_acc.append(epoch_acc.cpu()) else: valid_loss.append(epoch_loss) valid_acc.append(epoch_acc.cpu()) print('Epoch {} / {} (train) Loss: {:.4f}, Acc: {:.4f}, (val) Loss: {:.4f}, Acc: {:.4f}'.format(epoch + 1, num_epochs, train_loss[-1], train_acc[-1], valid_loss[-1], valid_acc[-1])) return train_loss, train_acc, valid_loss, valid_acc # モデルの定義 net = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, HIDDEN_SIZE, OUTPUT_SIZE, NUM_LAYERS) net.train() # 損失関数の定義 criterion = nn.CrossEntropyLoss() # 最適化手法の定義 optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9) num_epochs = 30 train_loss, train_acc, valid_loss, valid_acc = train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs)
結果は以下の通り。長いので省略。
NVIDIA GeForce GTX 1660 使用デバイス: cuda:0 Epoch 1 / 30 (train) Loss: 1.1939, Acc: 0.4245, (val) Loss: 1.1570, Acc: 0.4723 Epoch 2 / 30 (train) Loss: 1.1541, Acc: 0.4723, (val) Loss: 1.1453, Acc: 0.4880 Epoch 3 / 30 (train) Loss: 1.1439, Acc: 0.4954, (val) Loss: 1.1292, Acc: 0.4955 Epoch 4 / 30 (train) Loss: 1.1243, Acc: 0.5231, (val) Loss: 1.0985, Acc: 0.5397 Epoch 5 / 30 (train) Loss: 1.0570, Acc: 0.5846, (val) Loss: 0.9591, Acc: 0.6514 Epoch 6 / 30 (train) Loss: 0.9106, Acc: 0.6781, (val) Loss: 0.8848, Acc: 0.6874 Epoch 7 / 30 (train) Loss: 0.8063, Acc: 0.7278, (val) Loss: 0.8001, Acc: 0.7264 ... Epoch 27 / 30 (train) Loss: 0.1284, Acc: 0.9657, (val) Loss: 1.0355, Acc: 0.7631 Epoch 28 / 30 (train) Loss: 0.1462, Acc: 0.9555, (val) Loss: 0.9915, Acc: 0.7826 Epoch 29 / 30 (train) Loss: 0.1302, Acc: 0.9610, (val) Loss: 0.9754, Acc: 0.7826 Epoch 30 / 30 (train) Loss: 0.1221, Acc: 0.9641, (val) Loss: 0.9957, Acc: 0.7789
ちなみにロス、精度の推移は以下の通りです
import matplotlib.pyplot as plt fig, ax = plt.subplots(1,2, figsize=(10, 5)) epochs = np.arange(num_epochs) ax[0].plot(epochs, train_loss, label='train') ax[0].plot(epochs, valid_loss, label='valid') ax[0].set_title('loss') ax[0].set_xlabel('epoch') ax[0].set_ylabel('loss') ax[1].plot(epochs, train_acc, label='train') ax[1].plot(epochs, valid_acc, label='valid') ax[1].set_title('acc') ax[1].set_xlabel('epoch') ax[1].set_ylabel('acc') ax[0].legend(loc='best') ax[1].legend(loc='best') plt.tight_layout() plt.savefig('fig83.png') plt.show()
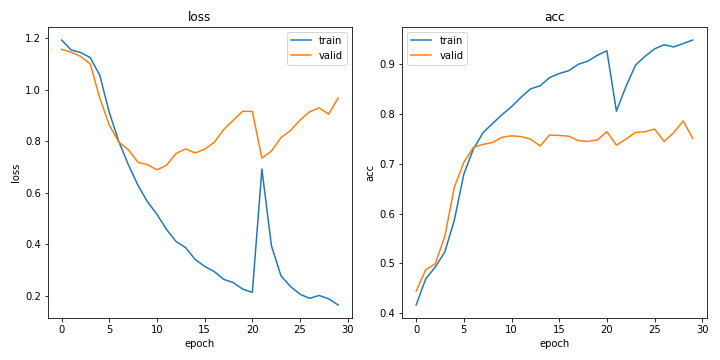
なんかすごく過学習してる気がしますが、まぁいいでしょう。
最後に正解率を計算しておきましょう。
def calc_acc(net, dataloader): device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") net.eval() corrects = 0 with torch.no_grad(): for inputs, labels in dataloader: inputs = inputs.to(device) labels = labels.to(device) outputs = net(inputs) _, preds = torch.max(outputs, 1) # ラベルを予想 corrects += torch.sum(preds == labels.data).cpu() return corrects / len(dataloader.dataset) acc_train = calc_acc(net, train_dataloader) acc_valid = calc_acc(net, valid_dataloader) acc_test = calc_acc(net, test_dataloader) print('学習データの正解率: {:.4f}'.format(acc_train)) print('検証データの正解率: {:.4f}'.format(acc_valid)) print('テストデータの正解率: {:.4f}'.format(acc_test))
学習データの正解率: 0.9718 検証データの正解率: 0.7811 テストデータの正解率: 0.7894
テストデータで78.9%でした。前回の多層ニューラルネットワークより悪いのはなんか納得いかないですね。。。
84. 単語ベクトルの導入
事前学習済みの単語ベクトル(例えば,Google Newsデータセット(約1,000億単語)での学習済み単語ベクトル)で単語埋め込みemb(x)を初期化し,学習せよ.
今回作成した単語の辞書を使用して各IDにおける事前学習済みの単語ベクトルを求めます。
事前学習のデータに含まれていないものは適当に正規分布で初期化しておきます。
from gensim.models import KeyedVectors # 学習済みモデルのロード file = './input/section7/GoogleNews-vectors-negative300.bin.gz' model = KeyedVectors.load_word2vec_format(file, binary=True) # 学習済み単語ベクトルの取得 VOCAB_SIZE = len(set(word2id.values())) + 2 EMB_SIZE = 300 weights = np.zeros((VOCAB_SIZE, EMB_SIZE)) words_in_pretrained = 0 for i, word in enumerate(word2id.keys()): try: weights[i] = model[word] words_in_pretrained += 1 except KeyError: weights[i] = np.random.normal(scale=0.1, size=(EMB_SIZE,)) weights = torch.from_numpy(weights.astype((np.float32))) print(f'学習済みベクトル利用単語数: {words_in_pretrained} / {VOCAB_SIZE}') print(weights.size())
出力は以下です
学習済みベクトル利用単語数: 9042 / 9725 torch.Size([9725, 300])
重みを設定できるようにモデルを変更して学習させます。
class RNN(nn.Module): def __init__(self, vocab_size, emb_size, padding_idx, hidden_size, output_size, num_layers=1, emb_weights=None): super().__init__() if emb_weights != None: self.emb = nn.Embedding.from_pretrained(emb_weights, padding_idx=padding_idx) else: self.emb = nn.Embedding(vocab_size, emb_size, padding_idx=padding_idx) self.rnn = nn.LSTM(emb_size, hidden_size, num_layers, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x, h0=None): x = self.emb(x) x, h = self.rnn(x, h0) x = x[:, -1, :] logits = self.fc(x) return logits # パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 2 # 辞書のID数 + unknown + パディングID EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) + 1 OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 NUM_LAYERS = 1 # モデルの定義 net = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, HIDDEN_SIZE, OUTPUT_SIZE, NUM_LAYERS, weights) net.train() # 損失関数の定義 criterion = nn.CrossEntropyLoss() # 最適化手法の定義 optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9) num_epochs = 30 train_loss_weights, train_acc_weights, valid_loss_weights, valid_acc_weights = train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs) fig, ax = plt.subplots(1,2, figsize=(10, 5)) epochs = np.arange(num_epochs) ax[0].plot(epochs, train_loss_weights, label='train') ax[0].plot(epochs, valid_loss_weights, label='valid') ax[0].set_title('loss') ax[0].set_xlabel('epoch') ax[0].set_ylabel('loss') ax[1].plot(epochs, train_acc_weights, label='train') ax[1].plot(epochs, valid_acc_weights, label='valid') ax[1].set_title('acc') ax[1].set_xlabel('epoch') ax[1].set_ylabel('acc') ax[0].legend(loc='best') ax[1].legend(loc='best') plt.tight_layout() plt.savefig('fig84.png') plt.show() acc_train = calc_acc(net, train_dataloader) acc_valid = calc_acc(net, valid_dataloader) acc_test = calc_acc(net, test_dataloader) print('学習データの正解率: {:.4f}'.format(acc_train)) print('検証データの正解率: {:.4f}'.format(acc_valid)) print('テストデータの正解率: {:.4f}'.format(acc_test))
出力は以下。
NVIDIA GeForce GTX 1660 使用デバイス: cuda:0 Epoch 1 / 30 (train) Loss: 1.1660, Acc: 0.4398, (val) Loss: 1.1375, Acc: 0.5075 Epoch 2 / 30 (train) Loss: 1.1138, Acc: 0.5175, (val) Loss: 1.0717, Acc: 0.6049 Epoch 3 / 30 (train) Loss: 1.0151, Acc: 0.6148, (val) Loss: 0.9327, Acc: 0.6709 Epoch 4 / 30 (train) Loss: 0.9457, Acc: 0.6557, (val) Loss: 0.9586, Acc: 0.6522 Epoch 5 / 30 (train) Loss: 0.8783, Acc: 0.6828, (val) Loss: 0.8820, Acc: 0.6799 ... Epoch 27 / 30 (train) Loss: 0.2266, Acc: 0.9182, (val) Loss: 0.6881, Acc: 0.8088 Epoch 28 / 30 (train) Loss: 0.1881, Acc: 0.9333, (val) Loss: 0.6482, Acc: 0.8141 Epoch 29 / 30 (train) Loss: 0.1815, Acc: 0.9350, (val) Loss: 0.8042, Acc: 0.7991 Epoch 30 / 30 (train) Loss: 0.1730, Acc: 0.9373, (val) Loss: 0.7646, Acc: 0.8133 学習データの正解率: 0.9481 検証データの正解率: 0.8133 テストデータの正解率: 0.8223
やや良くなりました。learning_rateそのままだと全然学習しなくなってしまったので上げました。
おわりに
時系列データの予測に強いといわれるRNNの実装をおこないました。文章データも単語の並びが重要なことも多いので、自然言語問題に多く使われてると理解しました。
ただ、今回の題材的にあまりうまく生かしきれなかった気がします。