はじめに
前回の続きで言語処理100本ノック解いていきたいと思います。
今回は第7章です。
第7章: 単語ベクトル
単語の類似度計算や単語アナロジーなどを通して,単語ベクトルの取り扱いを修得します.さらに,クラスタリングやベクトルの可視化を体験します.
単語の意味を実ベクトルで表現する単語ベクトル(単語埋め込み)に関して,以下の処理を行うプログラムを作成せよ.
60. 単語ベクトルの読み込みと表示
Google Newsデータセット(約1,000億単語)での学習済み単語ベクトル(300万単語・フレーズ,300次元)をダウンロードし,”United States”の単語ベクトルを表示せよ.ただし,”United States”は内部的には”United_States”と表現されていることに注意せよ.
単語ベクトルの読み取りにはgensimというライブラリを使用します。
from gensim.models import KeyedVectors file = './input/section7/GoogleNews-vectors-negative300.bin.gz' model = KeyedVectors.load_word2vec_format(file, binary=True) print(model['United_States'])
以下出力です。長いので省略します。
[-3.61328125e-02 -4.83398438e-02 2.35351562e-01 1.74804688e-01 -1.46484375e-01 -7.42187500e-02 -1.01562500e-01 -7.71484375e-02 1.09375000e-01 -5.71289062e-02 -1.48437500e-01 -6.00585938e-02 1.74804688e-01 -7.71484375e-02 2.58789062e-02 -7.66601562e-02 -3.80859375e-02 1.35742188e-01 3.75976562e-02 -4.19921875e-02 -3.56445312e-02 5.34667969e-02 3.68118286e-04 -1.66992188e-01 -1.17187500e-01 1.41601562e-01 -1.69921875e-01 -6.49414062e-02 -1.66992188e-01 1.00585938e-01 1.15722656e-01 -2.18750000e-01 -9.86328125e-02 -2.56347656e-02 1.23046875e-01 -3.54003906e-02 -1.58203125e-01 -1.60156250e-01 2.94189453e-02 8.15429688e-02 6.88476562e-02 1.87500000e-01 6.49414062e-02 1.15234375e-01 -2.27050781e-02 3.32031250e-01 -3.27148438e-02 1.77734375e-01 -2.08007812e-01 4.54101562e-02 -1.23901367e-02 1.19628906e-01 ...
61. 単語の類似度
“United States”と”U.S.”のコサイン類似度を計算せよ.
コサイン類似度もmodel.similarityで一瞬で計算できます。
print(model.similarity('United_States', 'U.S.'))
出力は以下。
0.73107743
62. 類似度の高い単語10件
“United States”とコサイン類似度が高い10語と,その類似度を出力せよ.
most_similarを使えば指定した単語にコサイン類似度が近い単語を指定の個数分取り出せます。
res = model.most_similar('United_States', topn=10) for i, x in enumerate(res): print('{}\t{}\t{}'.format(i + 1, x[0], x[1]))
出力は以下。
1 Unites_States 0.7877248525619507 2 Untied_States 0.7541370987892151 3 United_Sates 0.7400724291801453 4 U.S. 0.7310774326324463 5 theUnited_States 0.6404393911361694 6 America 0.6178410053253174 7 UnitedStates 0.6167312264442444 8 Europe 0.6132988929748535 9 countries 0.6044804453849792 10 Canada 0.601906955242157
63. 加法構成性によるアナロジー
“Spain”の単語ベクトルから”Madrid”のベクトルを引き,”Athens”のベクトルを足したベクトルを計算し,そのベクトルと類似度の高い10語とその類似度を出力せよ.
先ほどのmost_similarにて、足すベクトルをpositiveの引数に、引くベクトルをnegativeに指定してあげれば、先ほどとほぼ同じでOKです。
res = model.most_similar(positive=['Spain', 'Athens'], negative=['Madrid'], topn=10) for i, x in enumerate(res): print('{}\t{}\t{}'.format(i + 1, x[0], x[1]))
出力は以下です。
ギリシャは指定していないのにちゃんとコサイン類似度が高くなってますね。
1 Greece 0.6898480653762817 2 Aristeidis_Grigoriadis 0.560684859752655 3 Ioannis_Drymonakos 0.5552908778190613 4 Greeks 0.545068621635437 5 Ioannis_Christou 0.5400862097740173 6 Hrysopiyi_Devetzi 0.5248445272445679 7 Heraklio 0.5207759737968445 8 Athens_Greece 0.516880989074707 9 Lithuania 0.5166865587234497 10 Iraklion 0.5146791338920593
64. アナロジーデータでの実験
単語アナロジーの評価データをダウンロードし,vec(2列目の単語) - vec(1列目の単語) + vec(3列目の単語)を計算し,そのベクトルと類似度が最も高い単語と,その類似度を求めよ.求めた単語と類似度は,各事例の末尾に追記せよ.
これまでと同じことを大量にやればよいだけですね。
かなり時間がかかります。。。
":"から始まる行がそれ以降のカテゴリを示しているっぽいので各行の先頭にカテゴリを追加しておきます。
from tqdm import tqdm file2 = './input/section7/questions-words.txt' output = './input/section7/questions-words_similarity.txt' # tqdm用のtotal数を先に調べておく total = 0 with open(file2, 'r', encoding='utf-8') as f: for row in f: total += 1 category = '' with open(file2, 'r', encoding='utf-8') as f1, \ open(output, 'w', encoding='utf-8') as f2: for row in tqdm(f1, total=total): if row.startswith(':'): category = row.rstrip()[2:] continue else: cols = row.rstrip().split() word, similarity = model.most_similar(positive=[cols[1], cols[2]], negative=[cols[0]], topn=1)[0] f2.write('{}\t{}\t{}\t{}\n'.format(category, row.rstrip(), word, similarity))
出力ファイルの一部です。
capital-common-countries Athens Greece Baghdad Iraq Iraqi 0.635187029838562 capital-common-countries Athens Greece Bangkok Thailand Thailand 0.7137669324874878 capital-common-countries Athens Greece Beijing China China 0.7235778570175171 capital-common-countries Athens Greece Berlin Germany Germany 0.6734622716903687 capital-common-countries Athens Greece Bern Switzerland Switzerland 0.4919748306274414 capital-common-countries Athens Greece Cairo Egypt Egypt 0.7527808547019958 capital-common-countries Athens Greece Canberra Australia Australia 0.583732545375824 capital-common-countries Athens Greece Hanoi Vietnam Viet_Nam 0.6276341676712036 capital-common-countries Athens Greece Havana Cuba Cuba 0.6460990905761719 capital-common-countries Athens Greece Helsinki Finland Finland 0.68999844789505 capital-common-countries Athens Greece Islamabad Pakistan Pakistan 0.7233326435089111 capital-common-countries Athens Greece Kabul Afghanistan Afghan 0.6160916090011597 capital-common-countries Athens Greece London England Britain 0.5646188259124756 capital-common-countries Athens Greece Madrid Spain Spain 0.703661322593689 capital-common-countries Athens Greece Moscow Russia Russia 0.7382973432540894 capital-common-countries Athens Greece Oslo Norway Norway 0.6470744013786316 capital-common-countries Athens Greece Ottawa Canada Canada 0.5912168622016907 capital-common-countries Athens Greece Paris France France 0.6724624633789062 capital-common-countries Athens Greece Rome Italy Italy 0.6826190948486328
65. アナロジータスクでの正解率
64の実行結果を用い,意味的アナロジー(semantic analogy)と文法的アナロジー(syntactic analogy)の正解率を測定せよ.
これは正直問題文何言ってんだって感じでした。
問64でダウンロードしてきた評価データの4列目の単語と問64で求めたコサイン類似度が一番高い単語の一致数を調べればよさそうです。
意味的アナロジー(semantic analogy)と文法的アナロジー(syntactic analogy)に関しては、カテゴリ名がgramから始まるものが文法的アナロジーの評価データで、それ以外のカテゴリが意味的アナロジーとのことらしいので、それぞれ分けて正解率を計算します。
sem_cnt = 0 sem_true = 0 syn_cnt = 0 syn_true = 0 with open(output, 'r', encoding='utf-8') as f: for row in f: cols = row.strip().split('\t') target = cols[1].split()[-1] pred = cols[2] if not cols[0].startswith('gram'): sem_cnt += 1 if target == pred: sem_true += 1 else: syn_cnt += 1 if target == pred: syn_true += 1 print('意味的アナロジーの正解率: {}'.format(sem_true / sem_cnt)) print('文法的アナロジーの正解率: {}'.format(syn_true / syn_cnt))
出力は以下。
意味的アナロジーの正解率: 0.7308602999210734 文法的アナロジーの正解率: 0.7400468384074942
66. WordSimilarity-353での評価
The WordSimilarity-353 Test Collectionの評価データをダウンロードし,単語ベクトルにより計算される類似度のランキングと,人間の類似度判定のランキングの間のスピアマン相関係数を計算せよ.
スピアマン相関係数というのはいまいちよくわかってませんが、scipy.statsに関数が実装されているようです。
from scipy.stats import spearmanr file = './input/section7/combined.csv' human = [] w2v = [] with open(file, 'r', encoding='utf-8') as f: next(f) for row in f: cols = row.rstrip().split(',') human.append(float(cols[2])) w2v.append(model.similarity(cols[0], cols[1])) correlation, pvalue = spearmanr(human, w2v) print('スピアマン相関係数: {}'.format(correlation))
スピアマン相関係数: 0.7000166486272194
67. k-meansクラスタリング
国名に関する単語ベクトルを抽出し,k-meansクラスタリングをクラスタ数k=5として実行せよ.
教師なし機械学習ですね。
国名の単語がどこにあるのか謎ですが、先ほどのアナロジーデータから持ってくることにします。
まずは国名の取得及び単語ベクトルを取得します。
# 単語の取得 file = './input/section7/questions-words_similarity.txt' categories1 = ['capital-common-countries', 'capital-world'] categories2 = ['currency', 'gram6-nationality-adjective'] countries = set() with open(file, 'r', encoding='utf-8') as f: for row in f: cols = row.strip().split('\t') if cols[0] in categories1: country = cols[1].split()[1] countries.add(country) elif cols[0] in categories2: country = cols[1].split()[0] countries.add(country) else: continue countries = list(countries) print(len(countries)) print(countries) # 単語ベクトルの取得 countries_vec = [model[country] for country in countries]
129 ['Iceland', 'Ukraine', 'Botswana', 'Europe', 'Slovenia', 'Mauritania', 'Burundi', 'USA', 'Jamaica', 'Malaysia', 'Ghana', 'Iraq', 'Norway', 'Denmark', 'Azerbaijan', 'Germany', 'Rwanda', 'Ireland', 'Nicaragua', 'Colombia', 'Philippines', 'Cuba', 'Australia', 'Netherlands', 'Georgia', 'Spain', 'Somalia', 'Nigeria', 'Bhutan', 'Suriname', 'England', 'Madagascar', 'Romania', 'Jordan', 'Senegal', 'Tunisia', 'Russia', 'Moldova', 'Canada', 'Bulgaria', 'Austria', 'Greenland', 'Malawi', 'Hungary', 'Morocco', 'Afghanistan', 'Peru', 'Serbia', 'Belgium', 'Kyrgyzstan', 'Liberia', 'China', 'Guinea', 'Vietnam', 'Bahamas', 'Honduras', 'Ecuador', 'Portugal', 'Latvia', 'France', 'Fiji', 'Libya', 'Qatar', 'Venezuela', 'Italy', 'Indonesia', 'Angola', 'Cyprus', 'Belize', 'India', 'Pakistan', 'Zimbabwe', 'Oman', 'Bahrain', 'Syria', 'Niger', 'Malta', 'Turkey', 'Eritrea', 'Montenegro', 'Macedonia', 'Thailand', 'Finland', 'Armenia', 'Namibia', 'Japan', 'Mozambique', 'Cambodia', 'Algeria', 'Turkmenistan', 'Taiwan', 'Poland', 'Argentina', 'Laos', 'Guyana', 'Gabon', 'Egypt', 'Chile', 'Tuvalu', 'Korea', 'Samoa', 'Bangladesh', 'Lebanon', 'Dominica', 'Iran', 'Slovakia', 'Tajikistan', 'Gambia', 'Israel', 'Nepal', 'Sudan', 'Sweden', 'Mali', 'Estonia', 'Mexico', 'Uruguay', 'Greece', 'Kazakhstan', 'Zambia', 'Uzbekistan', 'Liechtenstein', 'Albania', 'Kenya', 'Lithuania', 'Switzerland', 'Uganda', 'Brazil', 'Belarus', 'Croatia']
全部で129個の国名の単語ベクトルを準備できました。
クラスタリングしていきます。sklearnのKMeansを使えば簡単にクラスタリングできます。
from sklearn.cluster import KMeans import numpy as np # k-meansクラスタリング kmeans = KMeans(n_clusters=5) kmeans.fit(countries_vec) for i in range(5): cluster = np.where(kmeans.labels_ == i)[0] print('cluster', i) print(', '.join([countries[k] for k in cluster]))
結果は以下です。
cluster 0 Jamaica, Nicaragua, Colombia, Cuba, Suriname, Peru, Bahamas, Honduras, Ecuador, Fiji, Venezuela, Belize, Argentina, Guyana, Chile, Tuvalu, Samoa, Dominica, Mexico, Uruguay, Brazil cluster 1 USA, Malaysia, Iraq, Philippines, Australia, Georgia, Jordan, Canada, Greenland, Morocco, China, Vietnam, Qatar, Indonesia, India, Oman, Bahrain, Thailand, Japan, Cambodia, Taiwan, Laos, Egypt, Korea, Lebanon, Israel cluster 2 Botswana, Mauritania, Burundi, Ghana, Rwanda, Somalia, Nigeria, Madagascar, Senegal, Tunisia, Malawi, Liberia, Guinea, Libya, Angola, Zimbabwe, Niger, Eritrea, Namibia, Mozambique, Algeria, Gabon, Gambia, Sudan, Mali, Zambia, Kenya, Uganda cluster 3 Ukraine, Azerbaijan, Bhutan, Russia, Moldova, Afghanistan, Kyrgyzstan, Pakistan, Syria, Armenia, Turkmenistan, Bangladesh, Iran, Tajikistan, Nepal, Kazakhstan, Uzbekistan, Belarus cluster 4 Iceland, Europe, Slovenia, Norway, Denmark, Germany, Ireland, Netherlands, Spain, England, Romania, Bulgaria, Austria, Hungary, Serbia, Belgium, Portugal, Latvia, France, Italy, Cyprus, Malta, Turkey, Montenegro, Macedonia, Finland, Poland, Slovakia, Sweden, Estonia, Greece, Liechtenstein, Albania, Lithuania, Switzerland, Croatia
単語ベクトルだけですが、地理的にも近そうな国がちゃんと同じクラスタになっている気がします。
68. Ward法によるクラスタリング
国名に関する単語ベクトルに対し,Ward法による階層型クラスタリングを実行せよ.さらに,クラスタリング結果をデンドログラムとして可視化せよ.
scipyでクラスタリング及びデンドログラムを扱えるライブラリがあるので使用します。
import matplotlib.pyplot as plt from scipy.cluster.hierarchy import linkage, dendrogram linkage_result = linkage(countries_vec, method='ward') plt.figure(figsize=(16, 9)) dendrogram(linkage_result, labels=countries) plt.savefig('fig68.png') plt.show()
結果は下記の通り

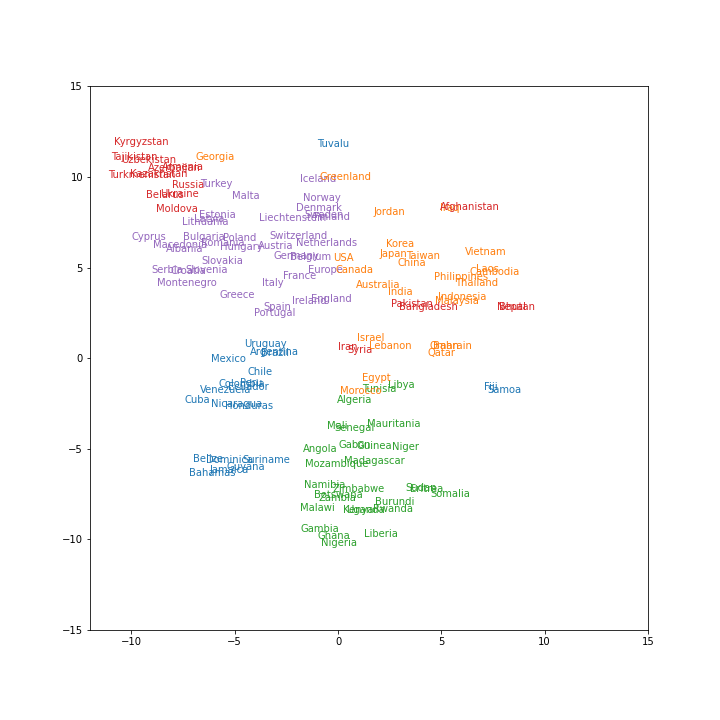
69. t-SNEによる可視化
ベクトル空間上の国名に関する単語ベクトルをt-SNEで可視化せよ.
t-SNEとは多次元ベクトルを次元低減する手法のようです。
sklearnに実装されてますので使ってみます。
可視化は、matplotlibのtextを使います。
from sklearn.manifold import TSNE tsne = TSNE(n_components=2, random_state=64) X_reduced = tsne.fit_transform(np.array(countries_vec)) plt.figure(figsize=(10, 10)) for x, country, color in zip(X_reduced, countries, kmeans.labels_): plt.text(x[0], x[1], country, color='C{}'.format(color)) plt.xlim([-12, 15]) plt.ylim([-15, 15]) plt.savefig('fig69.png') plt.show()
結果は以下
青と赤のクラスタが一部ばらついて分布してしまってるようですが、それ以外はちゃんとクラスタリングできてそうですね
おわりに
7章終わりです。
ライブラリに頼り切ってしまいましたが、ward法とかt-NSEの原理とかちゃんと調べてみようと思います。。。