はじめに
前回の続きで言語処理100本ノック解いていきたいと思います。
今回は第6章です。ついに機械学習の章です。
第6章: 機械学習
文書分類器を機械学習で構築します.さらに,機械学習手法の評価方法を学びます.
本章では,Fabio Gasparetti氏が公開しているNews Aggregator Data Setを用い,ニュース記事の見出しを「ビジネス」「科学技術」「エンターテイメント」「健康」のカテゴリに分類するタスク(カテゴリ分類)に取り組む.
50. データの入手・整形
News Aggregator Data Setをダウンロードし、以下の要領で学習データ(train.txt),検証データ(valid.txt),評価データ(test.txt)を作成せよ.
- ダウンロードしたzipファイルを解凍し,readme.txtの説明を読む.
- 情報源(publisher)が”Reuters”, “Huffington Post”, “Businessweek”, “Contactmusic.com”, “Daily Mail”の事例(記事)のみを抽出する.
- 抽出された事例をランダムに並び替える.
- 抽出された事例の80%を学習データ,残りの10%ずつを検証データと評価データに分割し,それぞれtrain.txt,valid.txt,test.txtというファイル名で保存する.ファイルには,1行に1事例を書き出すこととし,カテゴリ名と記事見出しのタブ区切り形式とせよ(このファイルは後に問題70で再利用する).
学習データと評価データを作成したら,各カテゴリの事例数を確認せよ.
問題文の通りデータを作成していきましょう。
まずは読み込みです。
import pandas as pd # ファイル読み込み file = './input/section6/newsCorpora.csv' data = pd.read_csv(file, encoding='utf-8', header=None, sep='\t', names=['ID', 'TITLE', 'URL', 'PUBLISHER', 'CATEGORY', 'STORY', 'HOSTNAME', 'TIMESTAMP']) data = data.replace('"', "'") data.head()
以下出力です。
| ID | TITLE | URL | PUBLISHER | CATEGORY | STORY | HOSTNAME | TIMESTAMP | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Fed official says weak data caused by weather, should not slow taper | http://www.latimes.com/business/money/la-fi-mo-federal-reserve-plosser-stimulus-economy-20140310,0,1312750.story\?track=rss | Los Angeles Times | b | ddUyU0VZz0BRneMioxUPQVP6sIxvM | www.latimes.com | 1394470370698 |
| 1 | 2 | Fed's Charles Plosser sees high bar for change in pace of tapering | http://www.livemint.com/Politics/H2EvwJSK2VE6OF7iK1g3PP/Feds-Charles-Plosser-sees-high-bar-for-change-in-pace-of-ta.html | Livemint | b | ddUyU0VZz0BRneMioxUPQVP6sIxvM | www.livemint.com | 1394470371207 |
| 2 | 3 | US open: Stocks fall after Fed official hints at accelerated tapering | http://www.ifamagazine.com/news/us-open-stocks-fall-after-fed-official-hints-at-accelerated-tapering-294436 | IFA Magazine | b | ddUyU0VZz0BRneMioxUPQVP6sIxvM | www.ifamagazine.com | 1394470371550 |
| 3 | 4 | Fed risks falling 'behind the curve', Charles Plosser says | http://www.ifamagazine.com/news/fed-risks-falling-behind-the-curve-charles-plosser-says-294430 | IFA Magazine | b | ddUyU0VZz0BRneMioxUPQVP6sIxvM | www.ifamagazine.com | 1394470371793 |
| 4 | 5 | Fed's Plosser: Nasty Weather Has Curbed Job Growth | http://www.moneynews.com/Economy/federal-reserve-charles-plosser-weather-job-growth/2014/03/10/id/557011 | Moneynews | b | ddUyU0VZz0BRneMioxUPQVP6sIxvM | www.moneynews.com | 1394470372027 |
次に特定のpublisherのみ抽出します。
# 特定のpublisherのみ抽出 publishers = ['Reuters', 'Huffington Post', 'Businessweek', 'Contactmusic.com', 'Daily Mail'] data = data.loc[data['PUBLISHER'].isin(publishers), ['TITLE', 'CATEGORY']].reset_index(drop=True) data.head()
| TITLE | CATEGORY | |
|---|---|---|
| 0 | Europe reaches crunch point on banking union | b |
| 1 | ECB FOCUS-Stronger euro drowns out ECB's message to keep rates low for ... | b |
| 2 | Euro Anxieties Wane as Bunds Top Treasuries, Spain Debt Rallies | b |
| 3 | Noyer Says Strong Euro Creates Unwarranted Economic Pressure (1) | b |
| 4 | REFILE-Bad loan triggers key feature in ECB bank test announcement- sources | b |
最後に、訓練用、評価用、テスト用に分けて保存するだけです。
# 学習用、検証用、評価用に分割する from sklearn.model_selection import train_test_split train, valid_test = train_test_split(data, test_size=0.2, shuffle=True, random_state=64, stratify=data['CATEGORY']) valid, test = train_test_split(valid_test, test_size=0.5, shuffle=True, random_state=64, stratify=valid_test['CATEGORY']) # データの保存 train.to_csv('./input/section6/train.txt', sep='\t', index=False) valid.to_csv('./input/section6/valid.txt', sep='\t', index=False) test.to_csv('./input/section6/test.txt', sep='\t', index=False) # データ数の確認 print('学習データ') print(train['CATEGORY'].value_counts()) print('検証データ') print(valid['CATEGORY'].value_counts()) print('評価データ') print(test['CATEGORY'].value_counts())
ちゃんと同じくらいの比率で全カテゴリが分けられているのがわかります。
学習データ b 4502 e 4223 t 1219 m 728 Name: CATEGORY, dtype: int64 検証データ b 562 e 528 t 153 m 91 Name: CATEGORY, dtype: int64 評価データ b 563 e 528 t 152 m 91 Name: CATEGORY, dtype: int64
51. 特徴量抽出
学習データ,検証データ,評価データから特徴量を抽出し,それぞれtrain.feature.txt,valid.feature.txt,test.feature.txtというファイル名で保存せよ. なお,カテゴリ分類に有用そうな特徴量は各自で自由に設計せよ.記事の見出しを単語列に変換したものが最低限のベースラインとなるであろう.
特徴量は好きに作成していいとのことなので、まずは前処理します
import re from nltk import stem # データの結合 df = pd.concat([train, valid, test], axis=0).reset_index(drop=True) def preprocessing(text): # 記号の削除 text_clean = re.sub(r'[\"\'.,:;\(\)#\|\*\+\!\?#$%&/\]\[\{\}]', '', text) # ' - 'みたいなつなぎ文字を削除 text_clean = re.sub('\s-\s', ' ', text_clean) # 数字の正規化(全部0にする) text_clean = re.sub('[0-9]+', '0', text_clean) # 小文字化 text_clean = text_clean.lower() # ステミングで語幹だけ取り出す stemmer = stem.PorterStemmer() res = [stemmer.stem(x) for x in text_clean.split()] return ' '.join(res) df['TITLE'] = df['TITLE'].apply(preprocessing) df.head()
前処理結果は以下。
| TITLE | CATEGORY | |
|---|---|---|
| 0 | justin bieber under investig for attempt robberi at dave buster | e |
| 1 | exxon report claim world highli unlik to limit fossil fuel despit risk | b |
| 2 | jack white record releas singl in hour for record store day 0 | e |
| 3 | presid barack obama releas proclam declar june lgbt pride | t |
| 4 | samsung share steadi after chairman heart attack | m |
変な記号とかもなくなって見やすくなりました。語幹処理したので変な英単語ばかりになってしまいましたが、何とかなることを祈りましょう。
特徴量としては、tf-idfベクトルを使用したいと思います。tf-idfとはざっくりいうと各文章の中で各単語の重要度の統計量を示しています。
scikit-learnにモジュールがあるので簡単に作成できます。
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(min_df=10, ngram_range=(1, 2)) # 1-gram, 2-gramでTfidfを計算 X = vectorizer.fit_transform(df['TITLE']).toarray() X_df = pd.DataFrame(X, columns=vectorizer.get_feature_names_out()) train_X = X_df.iloc[:len(train), :] # 訓練データの特徴量 valid_X = X_df.iloc[len(train):len(train)+ len(valid), :] # 評価データの特徴量 test_X = X_df.iloc[len(train)+ len(valid):, :] # テストデータの特徴量 train_X.to_csv('./input/section6/train.feature.txt', sep='\t', index=False) valid_X.to_csv('./input/section6/valid.feature.txt', sep='\t', index=False) test_X.to_csv('./input/section6/test.feature.txt', sep='\t', index=False) print(train_X.shape) # output # (10672, 3132)
3132単語分のTf-Tdfが求められました。なので、各文章3132個の特徴量を作成しました。
52. 学習
51で構築した学習データを用いて,ロジスティック回帰モデルを学習せよ.
scikit-learnで非常に簡単に学習プログラムは作成できます。
from sklearn.linear_model import LogisticRegression # モデルの学習 lg = LogisticRegression(random_state=64, max_iter=10000) lg.fit(train_X, train['CATEGORY'])
53. 予測
52で学習したロジスティック回帰モデルを用い,与えられた記事見出しからカテゴリとその予測確率を計算するプログラムを実装せよ.
lg.predictでラベルの予測、lg.predict_probaで各ラベルの予測確率が出力できます。
予測確率の一番大きいものが予測ラベルの予測確率なので、それを抽出しています。
import numpy as np def score(lg, X): pred = lg.predict(X) proba = np.max(lg.predict_proba(X), axis=1) return pred, proba train_pred, train_proba = score(lg, train_X) test_pred, test_proba = score(lg, test_X) print(train_pred) print(train_proba)
出力は以下です。
['e' 'b' 'e' ... 'b' 'b' 'b'] [0.86879699 0.44427864 0.77665809 ... 0.94968985 0.58099969 0.81744154]
54. 正解率の計測
52で学習したロジスティック回帰モデルの正解率を,学習データおよび評価データ上で計測せよ.
sklearn.metrics の accuracy_scoreを使えば正解率がすぐ求められます
from sklearn.metrics import accuracy_score train_accuracy = accuracy_score(train['CATEGORY'], train_pred) valid_accuracy = accuracy_score(valid['CATEGORY'], valid_pred) test_accuracy = accuracy_score(test['CATEGORY'], test_pred) print('正解率(学習データ):{}'.format(train_accuracy)) print('正解率(評価データ):{}'.format(valid_accuracy)) print('正解率(テストデータ):{}'.format(test_accuracy))
正解率(学習データ):0.931784107946027 正解率(評価データ):0.8875562218890555 正解率(テストデータ):0.9025487256371814
なんも調整してないのにテストデータで正解率0.9越えは結構いい結果じゃないでしょうか。
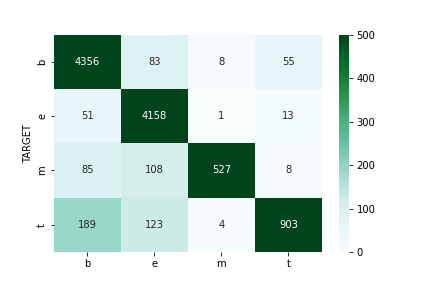
55. 混同行列の作成
52で学習したロジスティック回帰モデルの混同行列(confusion matrix)を,学習データおよび評価データ上で作成せよ
sklearn.metrics の confusion_matrixを使用すれば混同行列はすぐ求められます。
列名だけ調整して、グラフ化します。
from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt import seaborn as sns train_cm = confusion_matrix(train['CATEGORY'], train_pred) cm = pd.DataFrame(train_cm, columns=['b', 'e', 'm', 't']) cm['TARGET'] = ['b', 'e', 'm', 't'] cm = cm.set_index('TARGET') sns.heatmap(cm, vmin=0, vmax=500, annot=True, fmt='d', cmap='BuGn')
56. 適合率,再現率,F1スコアの計測
52で学習したロジスティック回帰モデルの適合率,再現率,F1スコアを,評価データ上で計測せよ.カテゴリごとに適合率,再現率,F1スコアを求め,カテゴリごとの性能をマイクロ平均(micro-average)とマクロ平均(macro-average)で統合せよ.
- 適合率:適合率(precision)は、陽性と予測されたサンプルのうち正解したサンプルの割合。
- 再現率(recall)は実際に陽性のサンプルのうち正解したサンプルの割合。
- F1値(F1-measure)は適合率と再現率の調和平均。
sklearn.metricsのclassification_report使用することですべて計算することが可能です。
from sklearn.metrics import classification_report print(classification_report(test['CATEGORY'], test_pred, labels=['b', 'e', 'm', 't']))
precision recall f1-score support
b 0.91 0.95 0.93 563
e 0.91 0.98 0.94 528
m 0.93 0.55 0.69 91
t 0.86 0.66 0.75 152
accuracy 0.90 1334
macro avg 0.90 0.79 0.83 1334
weighted avg 0.90 0.90 0.90 1334
57. 特徴量の重みの確認
52で学習したロジスティック回帰モデルの中で,重みの高い特徴量トップ10と,重みの低い特徴量トップ10を確認せよ
重みはlg.coef_で求めることができるので、ソートして表示します。
feature_names = train_X.columns.values for i in range(len(lg.classes_)): coef = lg.coef_[i] features = [(feature_names[j], np.abs(coef[j])) for j in range(len(feature_names))] print('カテゴリ: {} ================'.format(lg.classes_[i])) bests = sorted(features, key=lambda w: w[1], reverse=True) worsts = sorted(features, key=lambda w: w[1]) print('重みの高いtop10') for k in range(10): print('{}\t{}\t{}'.format(k + 1, bests[k][0], bests[k][1])) print('重みの低いtop10') for k in range(10): print('{}\t{}\t{}'.format(k + 1, worsts[k][0], worsts[k][1]))
カテゴリ: b ================ 重みの高いtop10 1 bank 3.689908611076508 2 fed 3.2848162251991115 3 china 3.1211406345591235 4 ecb 2.995397140034205 5 ukrain 2.583554577302779 6 profit 2.509900109275827 7 euro 2.4553695146477383 8 updat 2.422075617837872 9 oil 2.395072696909764 10 stock 2.3458313443387175 重みの低いtop10 1 normal 0.0003025127516367525 2 worri 0.0003960115772153317 3 part 0.0008720560254397 4 worth 0.001121113267886076 5 more than 0.0011850690219470524 6 everyon 0.0012069173139622623 7 process 0.0012348236031891496 8 favorit 0.0015815009799835726 9 two 0.001623582971074099 10 rel 0.0017065335269750297 カテゴリ: e ================ 重みの高いtop10 1 updat 3.1832900178206716 2 kardashian 2.7457994065080062 3 googl 2.6884240449992833 4 film 2.6055249027285527 5 chri 2.581960538131681 6 movi 2.4980308359802605 7 us 2.4799357782097236 8 wed 2.252579753723076 9 china 2.228863103397663 10 studi 2.226274973499316 重みの低いtop10 1 yr 0.00034237215683756797 2 ny 0.0008347440146016411 3 north 0.0011325889969546784 4 theori 0.002199262766617643 5 north american 0.002535352662013101 6 on us 0.002553481687604438 7 april 0.0029828164203294953 8 in may 0.003227777856529744 9 lawyer 0.0034553823660407952 10 ireland 0.0036978150677756346 カテゴリ: m ================ 重みの高いtop10 1 ebola 4.364410615578163 2 studi 4.090432719336458 3 fda 3.3996720957360482 4 cancer 3.370066849521253 5 drug 3.1939640345014317 6 cigarett 2.85022129023761 7 mer 2.796231829409237 8 doctor 2.617121581798108 9 cdc 2.5627967579211317 10 brain 2.5297257125234416 重みの低いtop10 1 defect 0.0008104422160824192 2 no longer 0.00129491372885117 3 due 0.0014419958472107924 4 the world 0.0018380035126619179 5 teva 0.0018954154831141749 6 jj 0.0019295043223728188 7 accord 0.0026154348964390487 8 crush 0.0026302860092439657 9 to 0.0026342579993977474 10 to close 0.0026640063461575284 カテゴリ: t ================ 重みの高いtop10 1 googl 5.179587698790135 2 facebook 4.471969378521285 3 appl 4.348392975702018 4 microsoft 3.974207395257876 5 climat 3.7880559765502335 6 tesla 3.122008478645007 7 gm 3.0373900350033183 8 nasa 2.9105822445433898 9 samsung 2.7179853744263394 10 fcc 2.701114299221962 重みの低いtop10 1 to make 0.0003457102897547669 2 kick off 0.0031307698625173772 3 around 0.0033043578843438117 4 museum 0.003910052687801942 5 craft 0.004003466330203036 6 warrant 0.004041697616290316 7 illinoi 0.004112044415676424 8 woe 0.004308188328350582 9 market 0.005084469596681079 10 maintain 0.0052924723703983425
58. 正則化パラメータの変更
ロジスティック回帰モデルを学習するとき,正則化パラメータを調整することで,学習時の過学習(overfitting)の度合いを制御できる.異なる正則化パラメータでロジスティック回帰モデルを学習し,学習データ,検証データ,および評価データ上の正解率を求めよ.実験の結果は,正則化パラメータを横軸,正解率を縦軸としたグラフにまとめよ.
正則化パラメータのCをいろいろ変えて結果をプロットします
from tqdm import tqdm results = [] for c in tqdm(np.logspace(-4, 2, 10, base=10)): # モデルの学習 lg = LogisticRegression(random_state=64, max_iter=10000, C=c) lg.fit(train_X, train['CATEGORY']) # 予測 train_pred = lg.predict(train_X) valid_pred = lg.predict(valid_X) test_pred = lg.predict(test_X) # 評価 train_acc = accuracy_score(train['CATEGORY'], train_pred) valid_acc = accuracy_score(valid['CATEGORY'], valid_pred) test_acc = accuracy_score(test['CATEGORY'], test_pred) results.append([c, train_acc, valid_acc, test_acc]) results = np.array(results) fig, ax = plt.subplots() ax.plot(results[:, 0], results[:, 1], label='train') ax.plot(results[:, 0], results[:, 2], label='valid') ax.plot(results[:, 0], results[:, 3], label='test') ax.set_xlabel('C') ax.set_ylabel('accuracy') ax.set_xscale('log') plt.show()

c=1~10くらいの間に設定するのがよさそうですね
59. ハイパーパラメータの探索
学習アルゴリズムや学習パラメータを変えながら,カテゴリ分類モデルを学習せよ.検証データ上の正解率が最も高くなる学習アルゴリズム・パラメータを求めよ.また,その学習アルゴリズム・パラメータを用いたときの評価データ上の正解率を求めよ.
optunaを使うことで自動でパラメータの探索を行えます。
今回はCを探索します。
import optuna # 目的関数の設定 def objective(trial): # 探索変数 c = trial.suggest_loguniform('C', 1, 1e1) # モデル lg = LogisticRegression(random_state=64, max_iter=10000, C=c, ) # 学習 lg.fit(train_X, train['CATEGORY']) # 検証 valid_pred = lg.predict(valid_X) valid_acc = accuracy_score(valid['CATEGORY'], valid_pred) return valid_acc # 最適化 study = optuna.create_study(direction='maximize') study.optimize(objective, timeout=30) # 結果の表示 print('Best trial:') trial = study.best_trial print(' Value: {:.3f}'.format(trial.value)) print(' Params: ') for key, value in trial.params.items(): print(' {}: {}'.format(key, value))
Best trial:
Value: 0.902
Params:
C: 5.881032344571771最後にこのパラメータを使用して予測した結果が下記です。
正解率(学習データ):0.9775112443778111 正解率(評価データ):0.9017991004497751 正解率(テストデータ):0.9092953523238381
おわりに
6章終わりです。
sklearnにはいろんなモジュールがそろっててかなり強力ですね。