
Googleスプレッドシートをpythonで新規作成したり、操作したりする方法について紹介します。
はじめに
pythonからスプレッドシートを操作する方法について勉強したのでまとめていきたいと思います。いろいろやり方があるようですが、私としては今回紹介する方法が一番簡単で使い勝手がいいと思いました。
事前準備
事前準備としてスプレッドシートを外部アプリから操作するための各種設定が必要になります。今回はその事前準備が終わった前提で解説していきますので、事前準備がまだの場合は下記記事を参考に実施してください。
スプレッドシートの操作テスト
事前準備にてclient_secret.jsonという認証用のファイルをダウンロードしたかと思いますが、今回作成するテスト用のプログラムと同じ階層にそのファイルを移動させておきます。
スプレッドシートの新規作成
まずはシートの作成をやってみましょう。
gspreadというライブラリで認証やスプレッドシートの操作等全部行えます。
import gspread import os dir_path = os.path.dirname(__file__) # 作業フォルダの取得 gc = gspread.oauth( credentials_filename=os.path.join(dir_path, "client_secret.json"), # 認証用のJSONファイル authorized_user_filename=os.path.join(dir_path, "authorized_user.json"), # 証明書の出力ファイル ) wb = gc.create("test01") # スプレッドシート作成
gspread.oauth()関数のcredentials_filenameオプションには認証用のJSONファイルパスを入れます。authorized_user_filenameオプションは初回認証後に生成される認証済みユーザの証明書の出力先ファイルパスを指定します。
※ファイルパスは絶対パスじゃないとうまくいかなかったです。
初回実行時は自動的にWebブラウザが起動して承認を求めてきます。スクショとり逃したので画像がないですが、自分のGoogleアカウントの選択と、アクセス権の承認を行います。アクセス権の承認はすべてにチェックを入れて続行をクリックすればOKです。2回目からは何も起きませんがちゃんとプログラムは動きます。
承認が終わると"The authentication flow has completed. You may close this window."とブラウザに表示されるのでここまで来たらブラウザは閉じでOKです。
その後数秒でプログラムが正常に終了します。出力は何もないですが、グーグルドライブを確認するとはtest01という名前でシートが無事作成されていました。
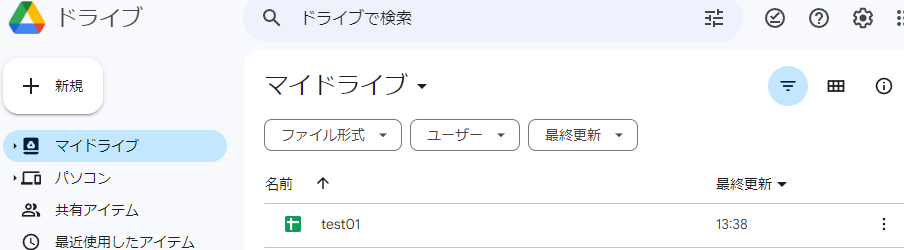
注意点
ファイル作成の際、同じ名前で何度も作れてしまうのでキーを取得しておきましょう。
試しに3つ作ってみます。
import gspread import os dir_path = os.path.dirname(__file__) gc = gspread.oauth( credentials_filename=os.path.join(dir_path, "client_secret.json"), authorized_user_filename=os.path.join(dir_path, "authorized_user.json"), ) for i in range(3): wb = gc.create("test01") print(wb.title, wb.id) # ファイル名とキーの出力
以下出力です。
test01 1zCzNOVk3... test01 1aeAZ9Srn... test01 1QFEdHEk...
3つとも同じファイル名ですが、キーが全部違うので異なるファイルです。
後々ファイルを開く際にファイル名を指定したりするとトラブルの元になりますので、ファイル生成の際はキーも一緒に確認してキー指定でファイルを開けるようにしておくことをすすめます。
ちなみにキーはスプレッドシートのURLからも確認できます。スプレッドシートを開いてURLを見てみると以下のような形になってます。
https://docs.google.com/spreadsheets/d/********/edit#gid=0
↑の********の部分がキーです。
スプレッドシートに書き込み
続いて書き込みをやってみたいと思います。test02というファイルを作成して、そこにデータを書き込んでいきます。
ファイルを開くのはファイル名指定でもできます。gc.open(ファイル名)でファイルを開くことができます。ただ、先ほど言ったようにファイルは同じ名前で何度も作れてしまいます。その場合最後に生成した同じ名前のファイルが選択されてしまいます。
今回はtest02というファイル生成時にキーを取得しておいて、gc.open_by_key(ファイルのキー)を使って、キーで開くことにします。
import gspread import os dir_path = os.path.dirname(__file__) gc = gspread.oauth( credentials_filename=os.path.join(dir_path, "client_secret.json"), authorized_user_filename=os.path.join(dir_path, "authorized_user.json"), ) # スプレッドシート生成 wb = gc.create("test02") # test02のファイルを作成 print(wb.id) # キーを後々の参照用に出力しておく # スプレッドシートに書き込み wb = gc.open_by_key(wb.id) # test02のファイルを開く(キーから) ws = wb.get_worksheet(0) # 最初のシートを開く(idは0始まりの整数) data = [ ['num1', 'num2', 'date', 'comment'], [1, 2, '2023/01/01', '寒い'], [3, 20, '2023/02/01', 'ふつう'], [31, 14, '2023/03/21', '暑い'], [16, 32, '2023/04/22', 'だるい'], [13, 100, '2023/05/03', '微熱がある'], ] # 複数行一括書き込み ws.append_rows(data) # 単行書き込み ws.append_row([0, -11, '2023/05/04', '単行書き込み'])
書き込む際はまず書き込み先のシートを指定する必要があります。今回はスプレッドシートのメソッドである.get_worksheet()をつかってインデックス番号からシートを指定しました。
インデックス番号は0始まりの整数で0を入れれば最初のシートが選択されます。(この場合はシート1)
シートのメソッド.append_rows()で2次元配列のリストを一括で書き込めます。
特に指定しない場合、A列のデータがない箇所から勝手に書き込みしてくれます。
.append_row()は単行書き込みで1次元配列のリストから一行分書き込みます。
こちらも同様に既にデータがあれば、データがない位置から勝手に書き込んでくれます
結果は以下です。
ちゃんと順番に書き込まれていることがわかりますね。
ただ、数字はちゃんと数字として打ち込めてますが、日付のほうは全部文字列型になっていますね。
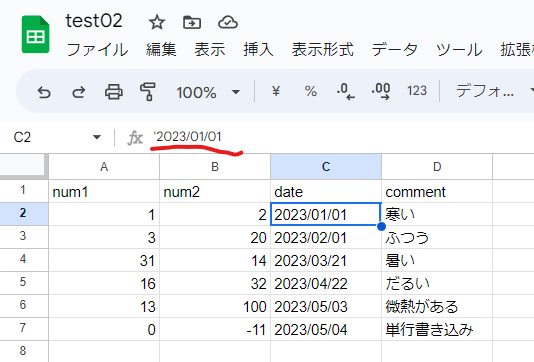
日付を日付として書き込む方法
これを解決するためには、append_rows()やappend_row()のvalue_input_optionオプションを指定してあげる必要があります。
import gspread import os import pandas as pd dir_path = os.path.dirname(__file__) gc = gspread.oauth( credentials_filename=os.path.join(dir_path, "client_secret.json"), authorized_user_filename=os.path.join(dir_path, "authorized_user.json"), ) wb = gc.create("test03") # test03のファイルを作成 print(wb.id) # wb = gc.open_by_key('1lnCl9-UQxNXO76jDjAcYSNIEQAuXb6xUXqs6M1KjF4I') wb = gc.open_by_key(wb.id) # test03のファイルを開く(キーから) ws = wb.get_worksheet(0) # 最初のシートを開く(idは0始まりの整数) print(ws.title) data = [ ['num1', 'num2', 'date', 'comment'], [1, 2, '2023/01/01', '寒い'], [3, 20, '2023/02/01', 'ふつう'], [31, 14, '2023/03/21', '暑い'], [16, 32, '2023/04/22', 'だるい'], [13, 100, '2023/05/03', '微熱がある'], ] # 複数行一括書き込み ws.append_rows(data, value_input_option='USER_ENTERED')
value_input_option='USER_ENTERED'の場合は、ユーザーが UI に入力したかのように解析されます。
実際にスプレッドシートに手打ちするような感覚でしょうか。
結果は以下の通り。

スプレッドシート上ではちゃんと日付として読み込まれてそうです。
スプレッドシートから読み込み
先ほど作ったtest03のファイルを読み込んでみましょう。先ほど生成したファイルのキーを指定してスプレッドシートを開いてシート1のすべてのデータを読み込みます。
import gspread import os dir_path = os.path.dirname(__file__) gc = gspread.oauth( credentials_filename=os.path.join(dir_path, "client_secret.json"), authorized_user_filename=os.path.join(dir_path, "authorized_user.json"), ) wb = gc.open_by_key('*****') # *****にtest03ファイルのキーを入れる ws = wb.get_worksheet(0) # 最初のシートを開く(idは0始まりの整数) all_data = ws.get_values() print(all_data)
シートのメソッド.get_values()ですべてのデータを2次元配列リストとして読み込むことができます。
結果は以下です。
[['num1', 'num2', 'date', 'comment'], ['1', '2', '2023/01/01', '寒い'], ['3', '20', '2023/02/01', 'ふつう'], ['31', '14', '2023/03/21', '暑い'], ['16', '32', '2023/04/22', 'だるい'], ['13', '100', '2023/05/03', '微熱がある']]
スプレッドシート上では数字は数字として認識されていたはずですが、全部文字列として読み込んでしまいましたね。デフォルトの状態だと全セル文字列として読み込むようです。
数字を数字として読み込む方法
こちらも書き込みと同様にget_values()のvalue_render_optionを追加で指定してあげることで読み込むことができます。
import gspread import os dir_path = os.path.dirname(__file__) gc = gspread.oauth( credentials_filename=os.path.join(dir_path, "client_secret.json"), authorized_user_filename=os.path.join(dir_path, "authorized_user.json"), ) wb = gc.open_by_key('*****') # *****にtest03ファイルのキーを入れる ws = wb.get_worksheet(0) # 最初のシートを開く(idは0始まりの整数) all_data = ws.get_values(value_render_option='UNFORMATTED_VALUE') print(all_data)
結果は以下の通り
[['num1', 'num2', 'date', 'comment'], [1, 2, 44927, '寒い'], [3, 20, 44958, 'ふつう'], [31, 14, 45006, '暑い'], [16, 32, 45038, 'だるい'], [13, 100, 45049, '微熱がある']]
数字は数字として読み込めるようになりましたね。
ただ、日付がシリアルナンバーに変換されてしまっています。
日付を文字列として読み込む方法
数字は数字として読み込んで、日付はシリアルナンバーではなくスプレッドシートに表示されてる文字列で読み込みたいです。
この場合はdate_time_render_optionを追加で指定してあげればOKです。
all_data = ws.get_values(value_render_option='UNFORMATTED_VALUE', date_time_render_option='FORMATTED_STRING')
結果は以下の通り
[['num1', 'num2', 'date', 'comment'], [1, 2, '2023/01/01', '寒い'], [3, 20, '2023/02/01', 'ふつう'], [31, 14, '2023/03/21', '暑い'], [16, 32, '2023/04/22', 'だるい'], [13, 100, '2023/05/03', '微熱がある']]
ちゃんと読み込めましたね!!
pandasのDataFrame形式で読み込み
ついでに、表計算といえばpandasを使いたくなるのでpandasのDataFrame形式で読み出してみましょう。
1行目はカラム名として作ったので、1行目をカラム名として指定して読み出します。基本的に同じように.get_values()で読み出します。
import gspread import os import pandas as pd dir_path = os.path.dirname(__file__) gc = gspread.oauth( credentials_filename=os.path.join(dir_path, "client_secret.json"), authorized_user_filename=os.path.join(dir_path, "authorized_user.json"), ) wb = gc.open_by_key('*****') # *****にファイルtest03のキーを入れる ws = wb.get_worksheet(0) # 最初のシートを開く(idは0始まりの整数) # pandasのDataFrame形式で取り込み df = pd.DataFrame(ws.get_values(value_render_option='UNFORMATTED_VALUE', date_time_render_option='FORMATTED_STRING')[1:], columns=ws.get_values()[0]) print(df) print('---型も確認---') print(df.dtypes) # ついでに型も確認
結果は以下。
num1 num2 date comment 0 1 2 2023/01/01 寒い 1 3 20 2023/02/01 ふつう 2 31 14 2023/03/21 暑い 3 16 32 2023/04/22 だるい 4 13 100 2023/05/03 微熱がある ---型も確認--- num1 int64 num2 int64 date object comment object dtype: object
DataFrame形式で読み込むことができ、整数が入っていた個所はちゃんとint64型で認識されています。