設定ファイルを実際にどういうときに使うのか、実際の使用例を交えて説明します。
はじめに
前回設定ファイルの読み書きについて説明しましたが、でも使い道に関してはまだピンとこないかもしれません。
今回は、設定ファイル(yamlファイル)を実際にプログラムの中で使ってみて、実際の使用感を紹介しようと思います。
対象のプログラム
ちょっと前に作ったGoogleニュースから好きなキーワードのニュースの情報を抜き出してスプレッドシートに流し込むプログラムを作りましたが、それを対象に設定ファイルを盛り込んでみましょう。
対象のプログラムは以下の最後の全コードです
作成したプログラムの問題点
過去記事にて作成したプログラムは、情報の保存先のスプレッドシートのキーと、検索したいキーワードをプログラムの最初に指定しており、スプレッドシートのキーがNoneの場合は新しく作成し、そこに情報を流し込む形でした。
問題点は下記の2点です。主にユーザ目線で問題だと感じた点です。
- 2回目のプログラム起動時には、スプレッドシートのキーをプログラムに書き込んでおかなければいけない(初期のNoneのままだと同じ名前のスプレッドシートがどんどんできてしまう)
- 検索したいキーワードを変えたいとき、追加したいときはプログラムをいじらなければならない
設定ファイル(yamlファイル)を使ってみる
先ほど挙げた問題点を設定ファイル(yamlファイル)を使うことで解決したいと思います。
yamlファイルを書く
yamlファイルでスプレッドシートの情報や検索したいキーワードを管理します。
今回追加/変更する処理は以下になります。
- yamlファイルを読み取る
- スプレッドシートの情報がなければ新規作成し、yamlファイルに作成したスプレッドシートの情報を追記
- yamlファイルから検索キーワードの情報を読み取る
- 検索キーワードでスクレイピングして、スプレッドシートに書き込む
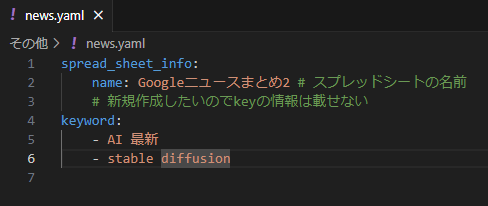
大体使い方のイメージはつきましたか?さっそくnews.yamlという名前でyamlファイルを作成します。
spread_sheet_info: name: Googleニュースまとめ2 # スプレッドシートの名前 # 新規作成したいのでkeyの情報は載せない key_word: - AI 最新 - stable diffusion
プログラムを改良する
まずはyamlファイルを読み取ってスプレッドシートの情報がなければ新規作成し、yamlファイルに作成したスプレッドシートの情報を追記してみましょう。
import gspread import os import yaml # スプレッドシート認証 dir_path = os.path.dirname(__file__) gc = gspread.oauth( credentials_filename=os.path.join(dir_path, "client_secret.json"), authorized_user_filename=os.path.join(dir_path, "authorized_user.json"), ) # yaml読み込み with open('news.yaml', 'rb') as f: yml = yaml.safe_load(f) # スプレッドシートのキーの情報がなければスプレッドシートを新規作成し、yamlファイルアップデート if 'key' not in list(yml['spread_sheet_info'].keys()): data = ['Date', 'Title', 'Publisher', 'Link'] wb = gc.create(yml['spread_sheet_info']['name']) # yamlからの情報に変更 KEY = wb.id wb = gc.open_by_key(KEY) # yamlファイル更新 yml['spread_sheet_info']['key'] = KEY with open('news.yaml', 'wb') as f: yaml.dump(yml, f, encoding='utf-8', allow_unicode=True) # キーワードもyamlファイルから for i, word in enumerate(yml['key_word']): if i == 0: ws = wb.get_worksheet(0) ws.update_title(word) else: wb.add_worksheet(title=word, rows=50, cols=10) ws = wb.worksheet(word) ws.append_row(data, value_input_option='USER_ENTERED')
更新されたyamlファイルは以下の通り。
key_word: - AI 最新 - stable diffusion spread_sheet_info: key: 1UbshXCbB........ name: Googleニュースまとめ2
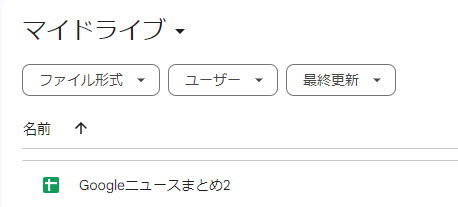
新しくスプレッドシートも作成でき、yamlファイルも自動でそのキーが入力されました。
これで二回目に実行時にわざわざキーの情報をプログラムに書き込む手間はなくなりました。
検索したいキーワードに関してもyamlファイルに追記、変更を行うだけでよくなるように、yamlファイルから読み取ったキーワードで同様にスクレイピング&書き出ししましょう
# スプレッドシートに書き込み wb = gc.open_by_key(yml['spread_sheet_info']['key']) for word in yml['key_word']: ws = wb.worksheet(word) res = get_news(word) ws.append_rows(res, value_input_option='USER_ENTERED')
結果は以下です。

これで最初に挙げた問題点はクリアできました。
最後に全コード載せておきます。
import gspread import os from bs4 import BeautifulSoup import requests import urllib.parse import datetime import yaml def get_news(key_word): key_word_encoded = urllib.parse.quote(key_word + ' when:1d') url = 'https://news.google.com/search?q={}&hl=ja&gl=JP&ceid=JP%3Aja'.format(key_word_encoded) res = requests.get(url) # urlにリクエストを送りレスポンスを取得 res.encoding = res.apparent_encoding # エンコーディング html_text = res.text # レスポンスのテキスト情報 soup = BeautifulSoup(html_text, 'html.parser') # html情報をBeautifulSoupで解析する articles = soup.find_all('article') # articleタグをすべて抜き出す base_url = 'https://news.google.com' print('今日の記事数{}個'.format(len(articles))) today = datetime.datetime.now().strftime('%Y/%m/%d') article_data = [] for article in articles: txt = article.find('h3') # articleタグ内のh3タグを抜き出す txt = txt.find('a') # 上のh3タグ内のaタグを抜き出す source = article.find_all('div')[0] # articleタグ内の最初のdivタグを抜き出す source_name = source.find('a').text article_data.append([today, txt.text, source_name, base_url + txt.get('href')[1:]]) return article_data # スプレッドシート認証 dir_path = os.path.dirname(__file__) gc = gspread.oauth( credentials_filename=os.path.join(dir_path, "client_secret.json"), authorized_user_filename=os.path.join(dir_path, "authorized_user.json"), ) # yaml読み込み with open('news.yaml', 'rb') as f: yml = yaml.safe_load(f) # スプレッドシートのキーの情報がなければスプレッドシートを新規作成し、yamlファイルアップデート if 'key' not in list(yml['spread_sheet_info'].keys()): data = ['Date', 'Title', 'Publisher', 'Link'] wb = gc.create(yml['spread_sheet_info']['name']) # yamlからの情報に変更 KEY = wb.id wb = gc.open_by_key(KEY) # yamlファイル更新 yml['spread_sheet_info']['key'] = KEY with open('news.yaml', 'wb') as f: yaml.dump(yml, f, encoding='utf-8', allow_unicode=True) # キーワードもyamlファイルから for i, word in enumerate(yml['key_word']): if i == 0: ws = wb.get_worksheet(0) ws.update_title(word) else: wb.add_worksheet(title=word, rows=50, cols=10) ws = wb.worksheet(word) ws.append_row(data, value_input_option='USER_ENTERED') # スプレッドシートに書き込み wb = gc.open_by_key(yml['spread_sheet_info']['key']) for word in yml['key_word']: ws = wb.worksheet(word) res = get_news(word) ws.append_rows(res, value_input_option='USER_ENTERED')