はじめに
過去の記事で正規分布に従うデータの分布の可視化について紹介しました。
製造業の品質管理等においても、基本的にデータが正規分布に従っている事が大前提なんですが、ちゃんと正規分布に従っているのかの確認をしている方は少ないような気がします。
今回はデータが正規分布に従っているかどうか判断する方法について調査、紹介します。
データの正規性の確認方法
以下の方法が主に使われます。
- ヒストグラムを目視
- 歪度、尖度を確認
- Q-Qプロットで確認
- シャピロウィルク検定
- コルモゴロフスミルノフ検定
順番にやってみましょう。
長くなりそうなので前半後半に分けることにします。
今回はヒストグラムと、歪度、尖度まで話します。
サンプルデータとして以下4つを使ってそれぞれの方法で確認してみます。
- ①正規分布に従うデータ
- ②ログ正規分布に従うデータ
- ③正規分布に従う2つの母集団からサンプリングしたデータ
- ④一様分布に従うデータ
データは以下コードで準備します。
実際の測定データをイメージして、データ点数少なめ(100個ずつ)でやってみます。
import numpy as np from scipy.stats import norm, lognorm, uniform # ①正規分布に従うサンプル data1 = norm.rvs(loc=7.5, scale=1, size=100) # ②ログ正規分布に従うサンプル data2 = lognorm.rvs(0.95, loc=5, scale=1, size=100) # ③2つの母集団からのサンプル data31 = norm.rvs(loc=10, scale=1, size=70) data32 = norm.rvs(loc=6, scale=1.5, size=30) data3 = np.concatenate([data31, data32]) # ④一様分布に従うサンプル data4 = uniform.rvs(loc=5,scale=8,size=100)
目視で確認
以前の記事で紹介したようにヒストグラムと、正規分布と仮定した際の確率密度関数をプロットします。
まずはヒストグラムのみプロットしてみます。
import matplotlib.pyplot as plt import seaborn as sns sns.set() fig, ax = plt.subplots(2, 2) ax[0, 0].hist(data1, density=True) ax[0, 0].set_xlabel('x') ax[0, 0].set_ylabel('density') ax[0, 0].set_title('1. Normal') ax[0, 0].set_xlim(0, 15) ax[0, 1].hist(data2, density=True) ax[0, 1].set_xlabel('x') ax[0, 1].set_ylabel('density') ax[0, 1].set_title('2. Log Normal') ax[0, 1].set_xlim(0, 15) ax[1, 0].hist(data3, density=True) ax[1, 0].set_xlabel('x') ax[1, 0].set_ylabel('density') ax[1, 0].set_title('3. Sample from two population') ax[1, 0].set_xlim(0, 15) ax[1, 1].hist(data4, density=True) ax[1, 1].set_xlabel('x') ax[1, 1].set_ylabel('density') ax[1, 1].set_title('4. Uniform') ax[1, 1].set_xlim(0, 15) plt.tight_layout() plt.show()
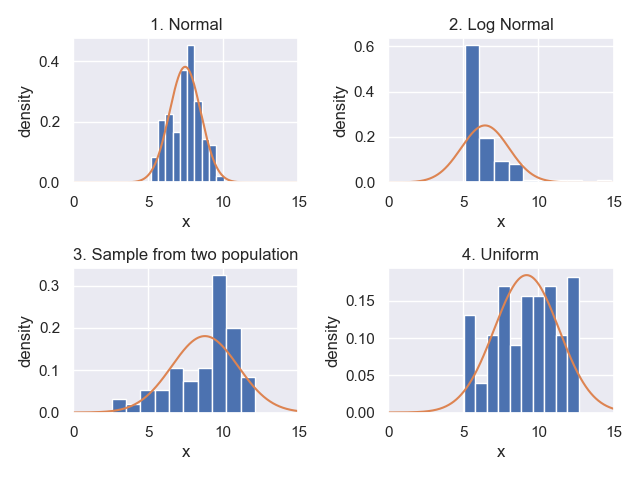
結果は以下の通り。

各測定データが正規分布と仮定した際の確率密度関数も重ねてみましょう。
各データの平均と標準偏差を求めて、正規分布の確率密度をプロットします。
x = np.linspace(0, 15, 1000) y1 = norm.pdf(x, loc=data1.mean(), scale=data1.std()) y2 = norm.pdf(x, loc=data2.mean(), scale=data2.std()) y3 = norm.pdf(x, loc=data3.mean(), scale=data3.std()) y4 = norm.pdf(x, loc=data4.mean(), scale=data4.std()) fig, ax = plt.subplots(2, 2) ax[0, 0].hist(data1, density=True) ax[0, 0].plot(x, y1) ax[0, 0].set_xlabel('x') ax[0, 0].set_ylabel('density') ax[0, 0].set_title('1. Normal') ax[0, 0].set_xlim(0, 15) ax[0, 1].hist(data2, density=True) ax[0, 1].plot(x, y2) ax[0, 1].set_xlabel('x') ax[0, 1].set_ylabel('density') ax[0, 1].set_title('2. Log Normal') ax[0, 1].set_xlim(0, 15) ax[1, 0].hist(data3, density=True) ax[1, 0].plot(x, y3) ax[1, 0].set_xlabel('x') ax[1, 0].set_ylabel('density') ax[1, 0].set_title('3. Sample from two population') ax[1, 0].set_xlim(0, 15) ax[1, 1].hist(data4, density=True) ax[1, 1].plot(x, y4) ax[1, 1].set_xlabel('x') ax[1, 1].set_ylabel('density') ax[1, 1].set_title('4. Uniform') ax[1, 1].set_xlim(0, 15) plt.tight_layout() plt.show()
正規分布に従う①以外のサンプルは分布と確率密度がかなりずれているのがわかるかと思います。
①に関しては何となくあってそうですね。
ただ、分布と確率密度の一致具合は感覚でしか言えないので、あまり理論的とは呼べない方法です。
ヒストグラムの級数の設定によっても分布形状が異なって見えることもあるので注意が必要です。
試しにbins=25でもう一度プロットしてみます。

①の正規分布に従っているものでも少し分布が変わって見えますね。
歪度、尖度を確認
続いて、歪度、尖度ですが、これは正規分布の形に近いかどうかの指標です。
歪度は分布の左右非対称の度合いを表す指標で、尖度は分布のとがり度合いを表す指標です。
正規分布の場合、歪度、尖度はともに0となります。
サンプルデータの分布の歪度、尖度がともに0に近ければ正規分布に近いと言えます。
scipy.statsにそれぞれモジュールが用意されていますので簡単に確認可能です。
歪度を確認
歪度は右に分布が偏ってると正の値、左だと負の値、左右対称だと0となります。
歪度を求めるコードは下記です。
from scipy.stats import skew print('1. 正規分布の歪度: ', skew(data1)) print('2. ログ正規分布の歪度: ', skew(data2)) print('3. 2つの母集団からサンプリングしたデータの歪度: ', skew(data3)) print('4. 一様分布の歪度: ', skew(data4))
1. 正規分布の歪度: -0.037493677491197724 2. ログ正規分布の歪度: 3.1258968469896 3. 2つの母集団からサンプリングしたデータの歪度: -0.869219627217025 4. 一様分布の歪度: -0.04110503171528328
先ほどの図を見るとわかりやすいですが、左右対称に近い形状の①正規分布のデータと④一様分布のデータの歪度が0にかなり近い値となっているのがわかります。
それ以外の分布は左右どちらかに偏っている形をしているので歪度の絶対値は①④と比較すると大きいです。
尖度を確認
尖度は正規分布のとがり度合いを0として、とがっていると正の値、なだらかだと負の値となります。
尖度を求めるコードは下記です。
# 尖度 from scipy.stats import kurtosis print('1. 正規分布の尖度: ', kurtosis(data1)) print('2. ログ正規分布の尖度: ', kurtosis(data2)) print('3. 2つの母集団からサンプリングしたデータの尖度: ', kurtosis(data3)) print('4. 一様分布の尖度: ', kurtosis(data4))
1. 正規分布の尖度: -0.6169132755417368 2. ログ正規分布の尖度: 10.950320162548241 3. 2つの母集団からサンプリングしたデータの尖度: 0.3225539701799911 4. 一様分布の尖度: -1.2297833915659981
目で見てもとがっているとわかる②のログ正規分布のデータは尖度が他と比べかなり大きな値となっています。
逆に平坦な分布である④の一様分布は負の値になっていますね。
歪度、尖度の閾値
残念なことに、歪度、尖度がどれくらいの値なら正規分布といっていいのかというのは明確に言えません。
ですが、正規分布に近いかどうかが数値でわかるので、どのデータが明らかに正規分布から外れているか?とか、どのデータが正規分布に近いか?といったことをパッと確かめるにはいい方法かもしれません。
